
Recognizes the document language using TextCat. Possible languages: german, english, french, spanish, italian, swedish, polish, dutch, norwegian, finnish, albanian, slovakian, slovenian, danish, hungarian.
N-Gram-Based Text Categorization
TextCat PR uses N-Gram for text categorization. You can find the details from this article. See the following diagram for its data flow.
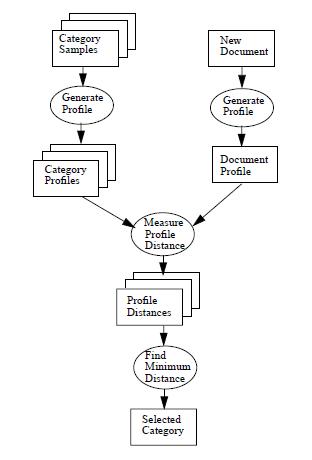
There are two phases in the language identification task:
- Training
- Application
We'll discuss those in the following sections.
Training Phase
In the training phase, the goal is to generate category profiles from the given category samples. In Language Identification PR (or TextCat PR), the categories are languages. So, we take document samples from different languages (i.e., English, German, etc.) and use them to generate category profiles.
These category profiles are already provided in TextCat PR. At runtime, TextCat PR looks for a configuration file named textcat.conf. This files has the following content:
language_fp/german.lm german
language_fp/english.lm english
language_fp/french.lm french
language_fp/spanish.lm spanish
language_fp/italian.lm italian
language_fp/swedish.lm swedish
language_fp/polish.lm polish
language_fp/dutch.lm dutch
language_fp/norwegian.lm norwegian
language_fp/finnish.lm finnish
language_fp/albanian.lm albanian
language_fp/slovak-ascii.lm slovakian
language_fp/slovenian-ascii.lm slovenian
language_fp/danish.lm danish
language_fp/hungarian.lm hungarian
In a sub-folder named language_fp which is relative to the location of textcat.conf, there are multiple category profile files with lm suffix. For example, german.lm is the category profile for German and english.lm is the category profile for English.
Using English profile as an example, its content looks like this:
_ 20326
e 6617
t 4843
o 3834
n 3653
i 3602
a 3433
s 2945
r 2921
h 2507
e_ 2000
d 1816
_t 1785
c 1639
l 1635
th 1535
he 1351
_th 1333
...
On each line, there are two elements:
- N-gram (N is from 1 to 5)
- Frequency
N-grams are sorted in the reverse order of frequency. For example, the most frequently found character in English documents is the space character (i.e., represented by '_') whose count of occurrences is 20326. From the training data, we also find that the most frequently found 2-gram is 'e_' (i.e., letter 'e' followed by a space).
Application Phase
In the application phase, the TextCat PR reads the learned model (i.e., category profiles ) and then applies the model to the data. Given a new document, first we generate a document profile (i.e., N-grams frequency profile) similar to the category profiles.
The language classification task is then to measure profile distance: For each N-gram in the document profile, we find its counterpart in the category profile, and then calculate how far out of place it is.
Finally, the bubble labelled "Find Minimum Distance" simply takes the distance measures from all of the category profiles to the document profile, and picks the smallest one.
What's in TextCat PR?
If you look inside the textcat-1.0.1.jar, you can identify the following structure:
org/
+--knallgrau/
+--utils/
+-- textcat/
+-- FingerPrint.java
+-- MyProperties.java
+-- NGramEntryComparator.java
+-- TextCategorizer.java
+-- textcat.conf
+-- language_fp/
+-- english.lm
+-- german.lm
+-- ...
Unfortunately, you cannot find the above source files from GATE's downloads. However, after Google search, I've found them from Google Code here.
2 comments:
There is SHOCKING news in the sports betting world.
It has been said that any bettor needs to look at this,
Watch this now or quit placing bets on sports...
Sports Cash System - Advanced Sports Betting Software.
Submit your website or blog now for appearing in Google and 300+ search engines!
Over 200,000 websites submitted!
SUBMIT RIGHT NOW with I NEED HITS!!!
Post a Comment