
6 Types of Memory Scopes
There are six types of memory scopes in a Fusion web application:- Application scope: An application scope object is available for the duration of the application and is shared among users. This scope may be used to hold static objects that are the same for all users.
- Session scope: The object is available for the duration of the session, which is user instance-specific. A use case for a session scope bean is a user info bean that stores information about a user, which is read from the database or an LDAP server, to avoid unnecessary queries.
- Page flow scope: A pageFlow scope exists for each task flow instance and has a lifespan between request and session scope. The lifetime of the scope spans across all pages in a bounded task flow.
- Request scope: The object is available from the time an HTTP request is made until a response is sent back to the client. From another perspective, a request scope starts with a request to be issued from one view to another for navigation cases that don't perform a redirect but a default server-side forward. The scope spans across all non-view activities that follow the view of interest to the next view activity.
- Backing bean scope: The backing bean scope is comparable to the request scope, with the difference in that it exists for a specific client component. In general, all managed beans used in reusable components should be configured to backingBean scope. For example, bounded task flows that are designed to be regions on a page should use the backingBean scope if more than one instance of the task flow is expected to be on a single page.
- View scope: The object is available until the view ID for the current view activity changes. This becomes handy when you use partial page rendering. If you have a dependent list box, you might send a server request to refresh the list box. When a response is returned, the request scope will be gone but the view scope will be still there. Therefore, view scope can be used to store data when partial rendering request comes back. The view scope exists not only for views that are rendered by JSPX pages, but also for views rendered by page fragments, as is the case in task flows that are built to execute in a region. The view scope of the parent page is not accessible from components added to a page fragement in a region, and the view scope of a view in a region is not accessible for the parent page.
When you create objects (such as a managed bean) that require you to define a scope, you can set the scope to none, meaning that it will not live within any particular scope, but will instead be instantiated each time it is referenced. You should set a bean's scope to none when it is referenced by another bean.
Note that page flow, backing bean, and view scope are not standard JSF scopes. You access objects in those scopes (under the hood they're java.util.Map's) via expression language with scope qualification. For instance, to reference the MyBean managed bean from pageFlowScope scope, your expression would be #{pageFlowScope.MyBean}.
A Managed Bean Example
In this tutorial provided by Frank Nimphius, it demonstrates the usage of a request-scoped managed bean (i.e., HandleCaptchaBean) which is defined in adfc-config.xml file:<adfc-config xmlns="http://xmlns.oracle.com/adf/controller" version="1.2">
<managed-bean>
<managed-bean-name>HandleCaptchaBean</managed-bean-name>
<managed-bean-class>adf.sample.HandleCaptchBean</managed-bean-class>
<managed-bean-scope>request</managed-bean-scope>
</managed-bean>
</adfc-config>At runtime, when user enters the challenged text and hit the try button, a method verifyAnswer defined on the managed bean would be invoked. The definition of the button looks like this:
<af:commandButton text="try" id="cb1"
actionListener="#{HandleCaptchaBean.verifyAnswer}"
partialSubmit="true" immediate="false"/>The text entered by the user would set a request-scoped attribute (i.e., bestGuess) as follows:<af:inputText id="it1" value="#{requestScope.bestGuess}"/>When the action listener verifyAnswer is executed, it would fetch the request-scoped attribute bestGuess in this way:
FacesContext fctx = FacesContext.getCurrentInstance();
ExternalContext ectx = fctx.getExternalContext();
String answer = (String) ectx.getRequestMap().get("bestGuess");Then fetched text is compared against the correct answer to see if the user is either a human or a robot.
ADF Task Flow
A task flow consists of activities and control flow cases that define the transitions between activities. Control flow rules are based on JSF navigation rules, but capture additional information. JSF navigation is always between pages, whereas control flow rules describe transitions between activities.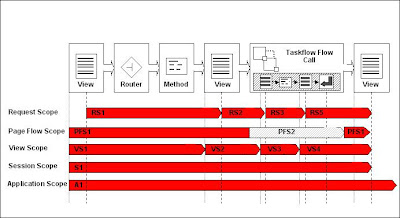
In the Figure, an unbounded task flow consists of a view activity, a router activity, a method call activity, a view activity, a bounded task flow, and a view activity and control flows in that order. There is one private scope per task flow, which is called page flow scope. When the outer task flow is executed, a new page flow scope PSF1 is created for it. When you enter the inner task flow, another page flow scope (i.e., PSF2) is created and PSF1 is suspended. After you exit from the inner task flow, PSF1 of the outer task flow is resumed. A task flow stack is maintained to keep track of the calls from task flow to task flow. An ADF Unbounded Task Flow always logically exists as the first entry on the task flow stack but would simply be empty.
When determining what scope to use for variables within a task flow, you should use any of the scope options other than application or session scope. These two scopes will persist objects in memory beyond the life of the task flow and therefore compromise the encapsulation and reusable aspects of a task flow. In addition, application and session scopes may keep objects in memory longer than needed, causing unneeded overhead.
Reusable components, especially those that are added with multiple instances on a single page, should be bound to per instance scope such as pageFlowScope, viewScope, or backingBean scope. If they are bound to broader scoped beans, many problems could ensue.
When you need to pass data values between activities within a task flow, you should use page flow scope. View scope is recommended for variables that are needed only within the current view activity, not across view activities. Request scope should be used when the scope does not need to persist longer than the current request. Lastly, backing bean scope must be used for backing beans in your task flow if there is a possibility that your task flow will appear in two region components or declarative components on the same page and you would like to achieve region instance isolation.
References
- Oracle Fusion Developer Guide by Frank Nimphius and Lynn Munsinger
- Creating and Using Managed Beans (if you use ADF Faces components in a standard JSF application)
- Using a Managed Bean in a Fusion Web Application (if you use Oracle ADF Model data binding and ADF Controller)
- JavaServer Faces (JSF) Tutorial
- Backing Bean in JSF Tutorial
- Managed Beans in Oracle Fusion Web Applications
No comments:
Post a Comment