To facilitate the review process, you need to present descriptions of entities and attributes in the data model to the functional team. Some database developers prefer working at source level (i.e., SQL DDL). For example, you can present the following EMP table to the team for review:
-- Employee Data
CREATE TABLE "SCOTT"."EMP"
(
"EMPNO" NUMBER(4,0), -- employee number
"ENAME" VARCHAR2(10 BYTE), -- employee name
"JOB" VARCHAR2(9 BYTE), -- job description
"MGR" NUMBER(4,0), -- manager ID
"HIREDATE" DATE, -- hiring date
"SAL" NUMBER(7,2), -- salary
"COMM" NUMBER(7,2), -- commission
"DEPTNO" NUMBER(2,0), -- department number
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO") USING INDEX PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT) TABLESPACE "USERS" ENABLE,
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO") REFERENCES "SCOTT"."DEPT" ("DEPTNO") ENABLE
)
In this article, we will show another way which presents the following table generated semi-automatically from the offline database using JDeveloper and Microsoft Excel: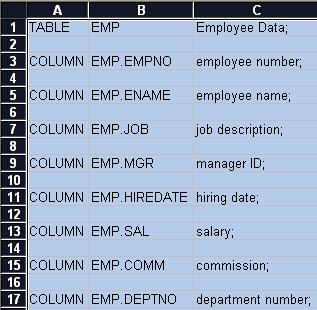

- SQL DDL scripts tend to be error-prone
- Comments are only for human reader and not part of the DB definitions
Offline Database
In JDeveloper, database development is available offline in the context of a project, allowing developers to create and manipulate schemas of database objects which can be generated to a database or to SQL scripts. Database objects can also be imported from a database into a project. See my previous post for more details.You can follow the instructions in [1, 2] to create offline database objects. For the demo, I've created a database diagram and drag an existing EMP table from the SCOTT schema to create a table on it.

Adding Comments
Double-click the EMP table component on the diagram to open the Edit Table dialog, Select Comment in the navigation panel to enter table's comment as shown above.
Select Comment in the navigation panel to enter table's comment as shown above. Select Columns in the navigation panel and navigate them one by one. In the Comment field, enter column's comment as shown above. Click Save All to save your work.
Select Columns in the navigation panel and navigate them one by one. In the Comment field, enter column's comment as shown above. Click Save All to save your work.In the Application Navigator, under Offline Database Sources | EMP_DATABASE | SCOTT, right-click the EMP node, and choose Generate To > SQL script ... to create SQL script file named emp.sql.
 Open emp.sql in the editor window. Look for comments of table's and columns' at the bottom of the script as shown below:
Open emp.sql in the editor window. Look for comments of table's and columns' at the bottom of the script as shown below:COMMENT ON TABLE EMP IS 'Employee Data'; COMMENT ON COLUMN EMP.EMPNO IS 'employee number'; COMMENT ON COLUMN EMP.ENAME IS 'employee name'; COMMENT ON COLUMN EMP.JOB IS 'job description'; COMMENT ON COLUMN EMP.MGR IS 'manager ID'; COMMENT ON COLUMN EMP.HIREDATE IS 'hiring date'; COMMENT ON COLUMN EMP.SAL IS 'salary'; COMMENT ON COLUMN EMP.COMM IS 'commission'; COMMENT ON COLUMN EMP.DEPTNO IS 'department number';
Select the above comments and copy them into a text file (i.e., emp.txt).
Generating Comment Table
Start up Microsoft Excel and import text file as follows: On the Text Import Wizard, you specify delimiters using space and paired single quotes as shown below:
On the Text Import Wizard, you specify delimiters using space and paired single quotes as shown below:
 After clicking on Finish button, you can remove column A,B, and E. It will then present you with the final comment table as shown at the beginning of this article.
After clicking on Finish button, you can remove column A,B, and E. It will then present you with the final comment table as shown at the beginning of this article.Conclusion
Comment tables generated in the second approach have the following advantages:- The source of comment table is offline database object which can be validated by JDeveloper and can be source controlled.
- They are part of the DB definitions and can be queried as follows:
select comments from user_tab_comments where table_name = 'EMP' /
select column_name, comments from user_col_comments where table_name = 'EMP' order by column_name /